1. 使用静态方法作为入口,不需要再new一个采集对象了。
2. 在第二个参数选择器数组中新增【标签列表】:可选,当【类型】值为text时表示需要保留的HTML标签,为html时表示要过滤掉的HTML标签
git地址:http://git.oschina.net/jae/QueryList
QueryList 新增交流社区:http://ql.44i.cc/
看下面实例代码:
//获取采集对象
$hj = QueryList::Query('http://www.baidu.com/s?wd=jaekj',array('title'=>array('h3','text')));
//输出结果:二维关联数组
print_r($hj->jsonArr);
//输出结果:JSON数据
echo $hj->getJSON();上面的代码实现的功能是采集百度搜索结果页面的所有搜索结果的标题,然后分别以数组和JSON格式输出。QueryList 使用入门教程(原文地址:http://ql.44i.cc/question/9)
以雷锋网为例,假设现在想要采集雷锋网首页的文章列表,按照下面步骤来(以谷歌浏览器为例):
1.打开雷锋网(http://www.leiphone.com/),可以观察到文章列表的样子如下图(点击放大)。
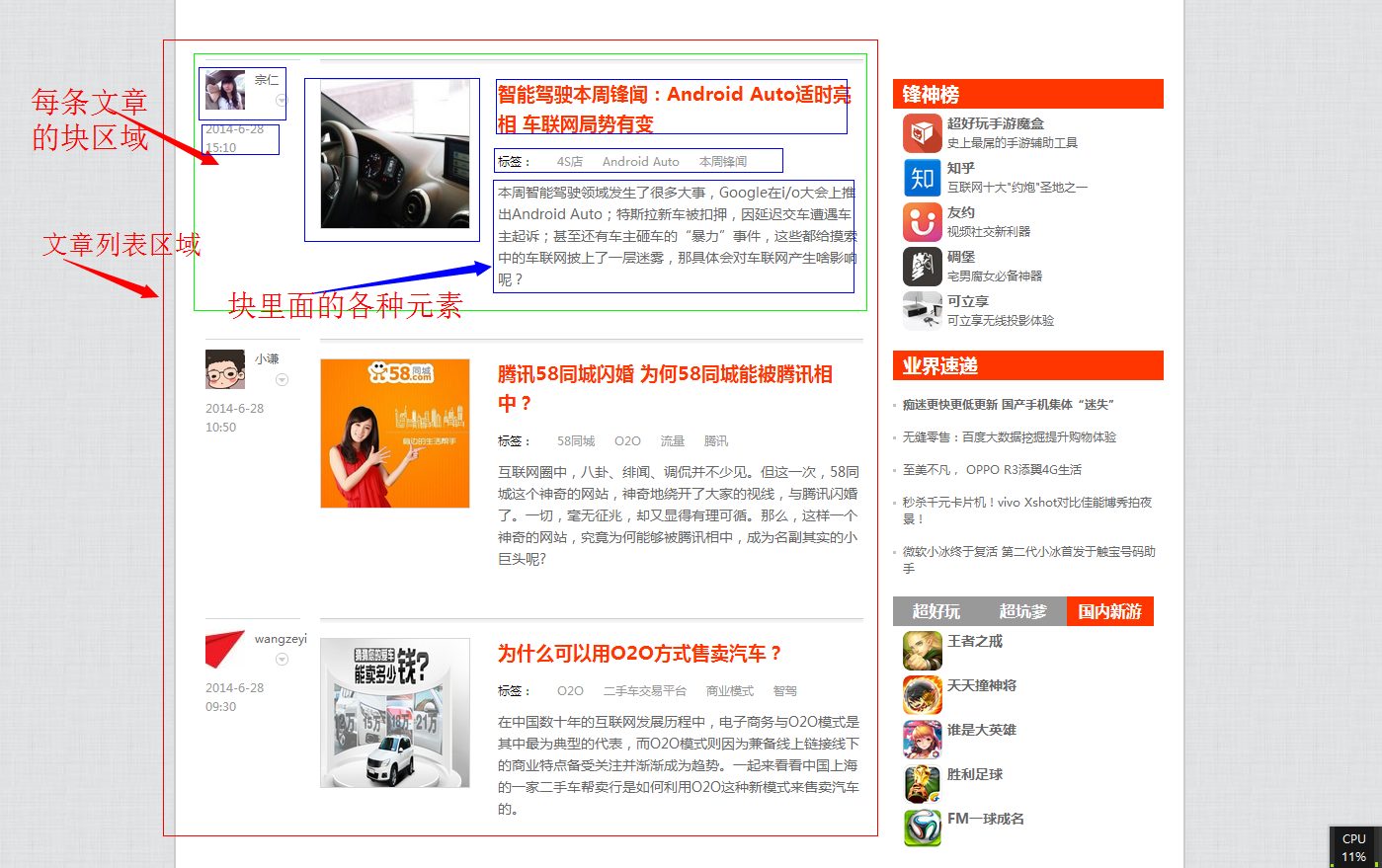
2.按快捷键 F12 或者 在网页上面右键选择 审查元素,调出开发者工具。
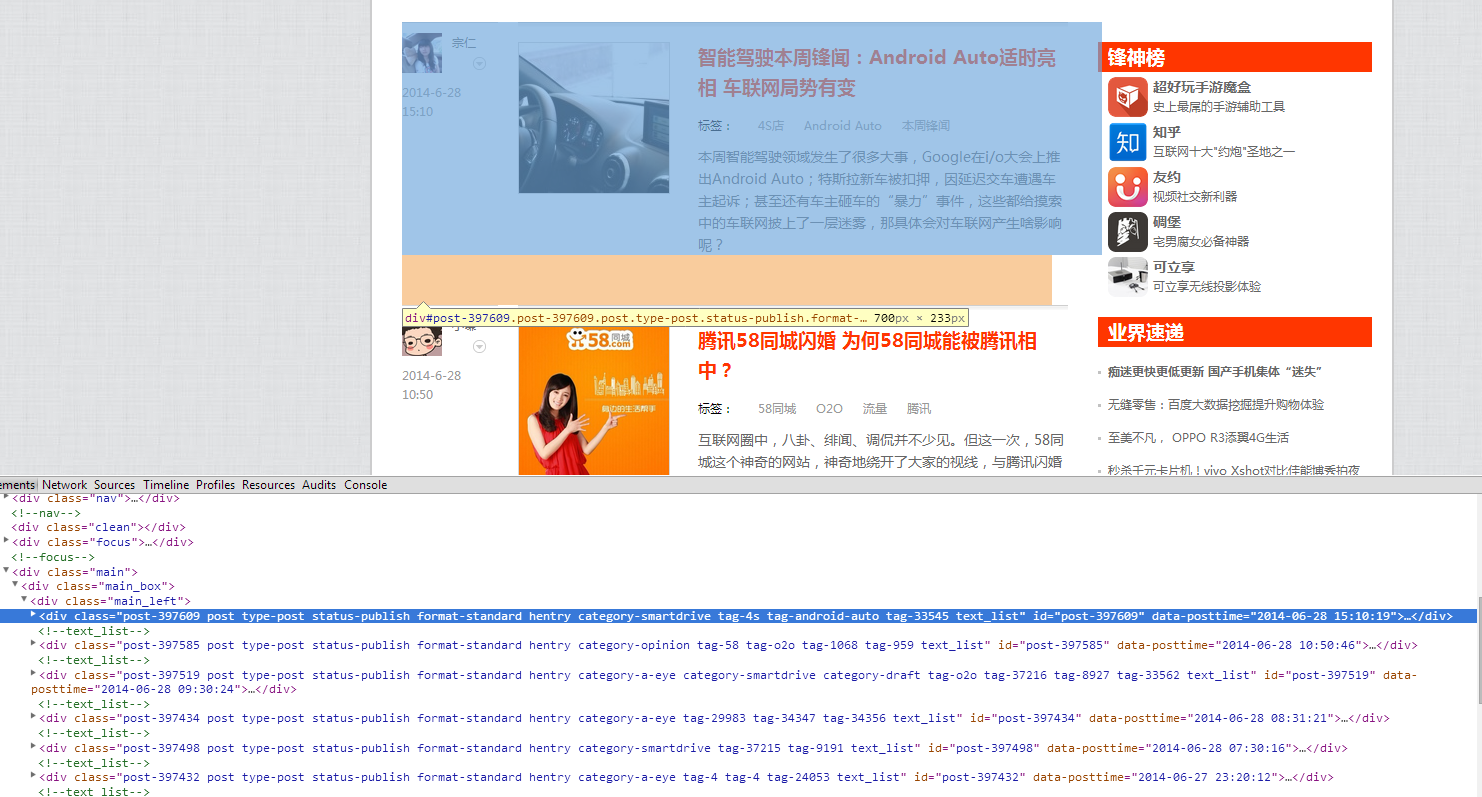
3. 首先我们获取块选择器,将指针放到每条文章块区域观察选择器,很容易就能观察到快选择器了(如下图),是每个 ID 以 post- 开头的div,那么块选择器就可以写成 [id^=post-] 。
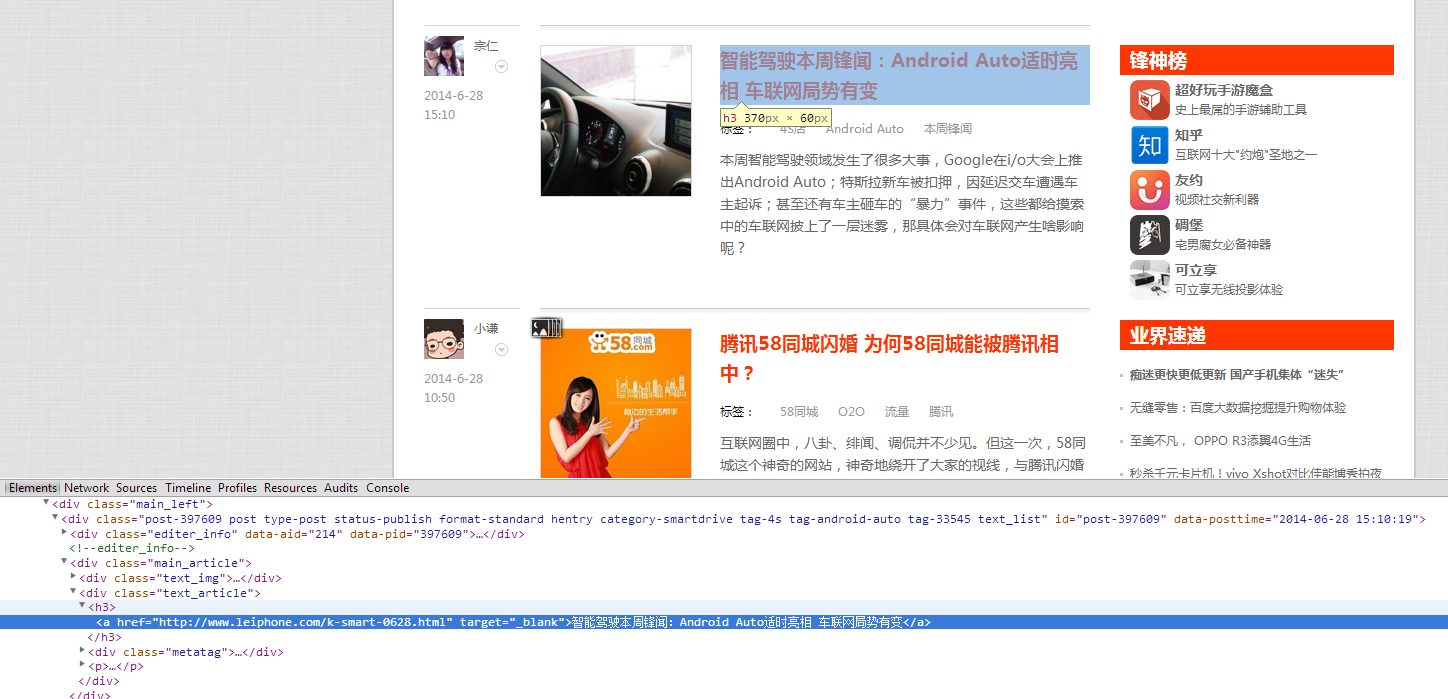
4. 现在比喻我要采集每条新闻的标题,将指针放到文章的标题上面,观察选择器(如下图),可以看到就是标题就是 h3 标签下的 a 标签,那么选择器就可以写成 h3 或者 h3>a 。
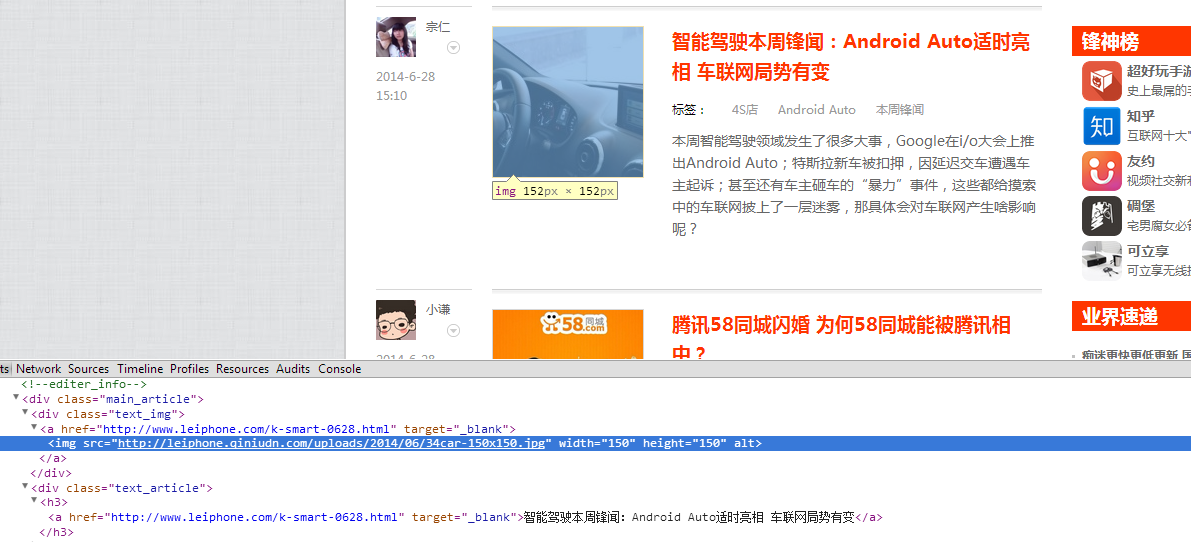
5. 比喻我现在还想获取每条文章的封面图片地址(如下图),同理可以得到选择器为 .text_img img ,取它的 src 属性就可以得到图片的链接地址了。
6.OK,得到选择器后下一步就是开始写PHP采集代码了,得到选择器再写代码就灰常简单了直接上代码。
//引入QueryList采集器
require 'ql/QueryList.class.php';
//要采集的目标网址
$url = "http://www.leiphone.com/";
//元素选择器
$reg = array(
"title" => array("h3","text"),
"img" => array(".text_img img","src")
);
//块选择器
$rang = "[id^=post-]";
//采集
$hj = QueryList::Query($url,$reg,$rang);
//输入采集结果
print_r($hj->jsonArr);如下图,灰常轻松的就采集回来了。
用本站的 采集语法 写下来就是这样子的,点击看看效果吧。
http://www.leiphone.com/|h3|[id^=post-]|text|UTF-8
最佳答案